Homongous! MongoDB, NoSQL and CQRS
Contents
Introduction
I’ve got what I consider to be a pretty good development stack - all the usual suspects: MVC for the front-end; data stored in SQL Server or MySQL and accessed via NHibernate with mappings using FluentNHibernate conventions; the domain model mapped to a view model using AutoMapper and a sprinkling of NInject dependency injection to tie it all together without direct dependencies.
And of course it works, it’s proven - lots of people use this approach. Lately though I’ve been reading a lot about different architectural approaches and in particular CQRS or ‘Command Query Responsibility Segregation’ from Udi Dahan and Greg Young which, among other things, promotes the idea of having a separate denormalized repository for querying data and another, possibly normalized relational database, for writing to.
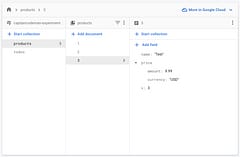
Because the query-side repository is denormalized it really lends itself to using a NoSQL approach which seems to be gaining ground so I thought I’d give it a try to see how well it would work using a forum app I’ve been re-developing (currently an MVC/NHibernate/SQL Server based app).
Now, it’s not facebook but it’s not trivial either - there are about 4m posts spread over 200k topics and I’ve done quite a bit of work on the database side of things to make sure it’s efficient and normalized. One feature I’m implementing is to go away from the old and boring topic list that most forums have (where they show the topic title, author, date, number of replies and sometimes the date and author of the latest reply) and present it more graphically with the avatar of the topic starter, the title, date and folder it’s in and then the avatars of the last 3 or more (depending on configuration) people who have replied. Here’s an example:

Now, to do this with the relational model means that I need to do quite a few table joins and when there are 4m+ rows that I need to be able to sort and page over it can start to chug a little. So, to speed things up I’ve spent some time optimizing the queries to use Indexed Views to combine the Topic, Folder and Author and Common Table Expressions (CTE) to get the last 3 replies which means joining the Topic, Post and Author tables again. It all works and it’s pretty quick but it’s been a lot of work to get it to that point.
So, the first test was to pick a NoSQL database to try as an alternative. I read up on quite a few and looked at the features and compatibility with Windows/C#/.NET including CouchDB, MongoDB, Cassandra, Voldemort and others and in the end decided to go with MongoDB.
Downloading and installing MongoDB (basically just unzipping the files) was easy and with the excellent documentation I was up and running really quickly and ready to start trying things out.
The first step was to try reading and writing documents using C# and this was really straightforward using the mongodb-csharp driver. So, next step was to convert the data from SQL Server into it. I already had the queries that created the paged views of data - typically with 10 or 20 records per page and thought I’d just re-use that. Running against the whole recordset really slowed it down though but after SQL Server chugged away for 10 or 15 minutes and used 6.5Gb of RAM it managed to give me the data and I created the JSON documents in-memory ready for inserting.
So, I call ‘Insert’ to add the collection of documents to the MongoDB store. And it failed. Well, actually … I assumed it failed because it only seemed to take about 5 seconds and my console app finished. When I went to the MongoDB console and queried the data though it was all there … and I could query it, sort it, page through it, very VERY quickly - much quicker than using SQL Server and the relational model. Windows process explorer showed MongoDB used just a few Mb of RAM to do this.
Because querying was so easy and so direct I no longer needed to use an OR/M to address the object-relational impedance mismatch (a fancy way of saying an RDBMS sucks for OO) and I no longer needed to transform the persistent domain model into a view model before presenting it. I can just get the view model objects straight from the store and render them. Fast, simple, and I get to delete lots of code which is kind of soul destroying when you’ve written it but I’m excited at all the code I won’t have to write in future with this approach and the performance.
MongoDB is very, very fast and very easy to use although it requires a slightly different way of thinking when you’re more used to working with a relational model. One of the big selling points is that it’s easier to scale than a relational system and while I didn’t try the sharding support (which is in alpha) I did give the replication a go - again, it was much easier to setup than the equivalent would be with SQL Server and it performed very well.
Finally, I did a few more experiments to test the insert performance compared to SQL Server and basically setup a simple table with an Id, Name and Number column and inserted 500,000 rows. I used parameterized queries for SQL Server, re-used the same command object and wrapped it all in a single transaction but it took over 55 seconds to run (plus I had to create the database and table in advance which took a minute or two). Doing the same thing with MongoDB ran in under 10 seconds and the client code was much simpler and I didn’t have any initial setup.
I’m definitely going to explore MongoDB more and plan on making use of it in future projects when it’s appropriate. The next piece to look at is the Command side of CQRS where I want to use event sourcing for storage and an event driven / service oriented architecture and better domain driven design techniques.