Building a Micro Startup Part 2: Design & Prototyping
Picking the right technologies
Contents
- Introduction
- Processing Engine
- Pattern Viewer
- Image (blob) Storage
- PDF Renderer
- Authentication
- Structured / Metadata Storage
- Payment Processing
- Final Design
Introduction
One of the mistakes I saw a lot of when Agile was taking off as “the hot-new thing” was people declaring that they didn’t need to do design anymore. Of course there was no big-upfront design - the kind from the waterfall days where people first analyzed and designed a system in full before punting it to the next team to build (which rarely worked out well) but some planning and design is important, even if you’re just creating a small hobby project.
Part of the process should often involve prototyping to help decide or prove which technologies you’re going to use as these will also factor in to the design of the app. It also gives you an opportunity to kick-the-tires of some technologies if they are things you haven’t used much before prior to building too many things around them. Making late-stage switches can be costly.
This isn’t going to be an exhaustive comparison of every possible client-side framework, storage technology or hosting option. Of course I have some technology choices in my head before I even begin based on my current skillset and experience (isn’t it an amazing coincidence that the “best” technology to build any app with is always the one the developer likes to use?!) But I’ll try to go through the reasoning behind some of the choices I came up with.
As you might recall from the first articles, Building a Micro Startup Part 1: Deciding on a Product / Service, we identified about half a dozen sub-systems or major components that the app will need. These are the parts that we need to pick technologies for and decide how they will work.
Processing Engine
This is what will take a photo or other image and perform the resizing and color resampling to produce the pattern. If I was building this system a decade or more ago I’d probably be thinking about using .NET and having this run on a Windows server. Urgh. That is of course still an option (although nowadays I’d likely be using a different language and platform) but there are issues with a server-side approach:
- Images would need to be uploaded before they can be used which adds friction
- It’s harder to auto-scale servers and load-balance if the temporary files are just on one of them
- Clean-up tasks are needed - when exactly has someone finished with an image?
- The bandwidth and system load usually means extra cost for me and for users
A simple thought process I like to follow is to think about what happens to a system with thousands or more users. If 10k people used the system 10 times each, would I want to host and store 100k images just for their “work in progress” while they tried things out? Probably not.
I know from recent experience on other projects that you can now do a lot of image processing on the client browser - resizing images, accessing the pixel data and applying filters - I have an image uploader that resizes images and converts them the WebP for faster uploading. Doing the processing on the users device would mean that the images stay local until and unless the user decides to save the pattern. That feels “right” as the point that we make something permanent (and could of course use localStorage in the meantime to allow for restarting and add some robustness). It also makes things a little friendlier if people have to pay a lot for bandwidth (e.g. mobile users).
So other than JavaScript + Canvas, not a lot to decide on although we’re probably going to limit support to the more modern “ever-green” browsers that have support for the newer features we need. Sorry (but not sorry) IE.
Pattern Viewer
We are going to need a viewer of some kind to be able to view the detail in patterns as people work on designing them and also to let them re-open a previously generated pattern (possibly to work from it with a phone or tablet). We already know we’re going to be developing a Progressive Web App and we’ll be using Canvas to do the image resizing so it makes sense to use that for the pattern as well. However, we’re not just displaying the pixels 1:1. A pattern of 600 stitches across might be considered large and detailed but it’s a relatively small image when you realize that a stitch is a pixel and patterns are made from symbols so it will need to allow zooming in so that each pixel becomes a readable character together with a grid.
Each pixel becomes a symbol in a square on the pattern:

While it would be simple to render this all to another canvas at the full detail level and then let people zoom in and pan around it, that’s going to be a much bigger image. Imagine each single pixel from the source image ends up as a 50x50 pixel square and symbol at the maximum zoom level - that 600 pixel image will now be 30,000 pixels across - into gigapixel territory which is going to cause major memory issues even on a powerful desktop and is never going to work on a mobile device. It also wouldn’t look great as we zoom in and out with symbols distorted due to resizing and grid-lines not sharp or looking blurry at anything lower than the fully zoomed in scale.
Instead we probably want to provide a virtual view of the pattern, a window onto it which renders just what the viewport can fit based on the current zoom level. If the users device is 300x500 pixels then that is all that will be rendered whatever part of the image they view and whatever the zoom level. The symbols can be rendered at the correct size and should look sharp too. Of course it will need to support desktop + mouse users as well as touch on mobile and tablets (swiping, pinch to zoom etc…).
We might be tempted to reach for one of the much-hyped JS frameworks such as Angular or React but while I’m sure it’s possible to build a perfectly decent component with them, I don’t want to be coupled to either of those frameworks - I don’t want to have to be upgrading framework dependencies and re-writing the app every 6 months because everything is outdated every time I have some time to pickup development again. I also want to avoid having to setup any complex build tools (more dependencies to manage and maintain) - I can write JS in JS and just run it directly which saves time and effort. Spend your time writing the code for your app, not writing code to try and make a framework run.
The web platform now provides an excellent and native component system in the form of the Web Components standard and this would be an ideal technology to build the viewer with. Web Components give us the ability to package up the HTML + CSS + JS as a custom element that can be used just like the existing HTML tags we might even be able to let people drop a <pattern-viewer src="some-pattern-url"></pattern-viewer> element on a blog page and have the user-interactive pattern appear. The Shadow DOM avoids other CSS or JS on a page interfering with the element.
It future proof’s things because browser platforms tend to evolve more slowly than JS frameworks as they live and are supported for much longer - decades instead of years at best with JS frameworks (or even months at worse). It’s already supported by Chrome and Safari and is coming for FireFox and Edge as well (but polyfill’ed in the meantime).
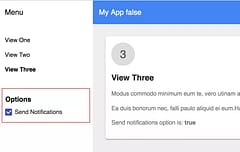
To prove it works and works well, I built a prototype to test out some ideas for the virtual zooming which you can see here:
I also wanted to try out some ideas for simplifying the UI options to avoid explicit view-mode options - instead it transitions smoothly between the image mode and symbol mode
We’re going to need more than the viewer though so pulling in “some” UI library will help with developing the other parts of the UI. My web-client library of choice right now is Polymer which has just turned 2.0. It’s nice because it adds just enough useful features (data binding, templating etc…) without being too heavyweight and intrusive like the rule-the-world JS frameworks. Because it’s build on Web Components and just adds a relatively thin layer on top, I see it as less risky and worth the tradeoff vs trying to do everything with pure web-components. It wouldn’t be a huge change to drop-down a level at some point to make the viewer more reusable but for now we’ll go with Polymer 2.0 for it and the rest of the web UI.
Image (blob) Storage
While the pattern processing is going to run on the client during the design process, at some point I am going to have to store them permanently. People work on patterns over years and I want to let them access the pattern again if they need to - storing it on a single server hard drive just won’t cut it, it has to be some replicated and secure storage.
I hadn’t decided at this point if I was going to store just the generated pattern or the source images as well - I have visions of letting people create variations of a pattern at different resolutions and it would be a shame if I was kicking myself in future because I needed the images and hadn’t stored them.
Google cloud storage is incredibly cheap and a no brainer for storing image blobs, it’s the Google equivalent of Amazon S3 or Azure erm … whatever it is they have. There are a few variations with different pricing depending on what your access patterns are going to be and whether you want regional or global buckets. I decided I’d just use the default bucket that is created automatically when you spin up a project which is the global one. They even give you 5Gb of storage for free which is enough for the first couple of thousand patterns to keep things at the zero-cost point initially and it’s only $0.026 per Gb / month after that. That’s before I even start thinking about optimizing the source image storage by using WebP.
So, I can store the patterns and the full source images - because why wouldn’t I?
PDF Renderer
Now we get to something that is more of an unknown. I have rendered PDFs in the past but was using iText, a .NET port of a Java library (and I don’t want to use either of those platforms). In the back of my head I’m hoping to be able to use AppEngine for any server-side code because I know its a great Platform as a Service that will save a lot of devops work and comes with a generous daily free-usage tier which will help control costs (if no one uses it, it would be nice if it didn’t cost anything!). As it’s part of the greater Google Cloud Platform I am confident that if it turns out that AppEngine isn’t suitable, there will be something else I can switch to instead. I’m sure Amazon Web Services or Microsoft Azure would be viable options too and I’ve used both in the past but Google Cloud Platform is the one I use most right now.
AppEngine Standard supports Python, PHP, Java and Go language runtimes. I have used Python and it works but I don’t want to invest new code in it. Same goes for Java (plus the higher runtime resource requirements could make it harder to keep to the free-tier). Sorry, but PHP is simply an abomination against all that is holy in the world and I curse it every time I connect a server online and it’s instantly probed by bots looking for vulnerabilities in well-known PHP apps. They do now offer a new “Flex” hosting which lets you bring your own runtime (or docker image) but it’s disproportionately expensive IMO so if I couldn’t use standard I’d think about switching to Compute Engine instances instead which are much less expensive.
That really leaves Go as the only option. But that’s OK, because Go is great! - it’s a joy to work with, easy to keep a codebase clean and it runs very fast even with very few resources so will usually work even within the AppEngine free usage tier with ease. This gives you 27-hours worth of the smallest F1 instance per day which only has 128Mb RAM and a 600Mhz CPU but Go can give you single-digit ms response times and use up less than 10Mb of RAM to do it.
But - can I render PDFs with Go and can I do it on the AppEngine Standard environment which is a sandboxed environment that can sometimes prevent libraries from running?
I had a look round and found 3 PDF libraries for Go - 2 open-source (signintech/gopdf and jung-kurt/gofpdf) plus a commercial one that needed an “expensive” license - too expensive for my budget … which is $0. Unfortunately it looked like neither of the open-source versions was fully complete with features that I might need although their APIs looked similar (same domain space and inspired by FPDF, a PHP library - shakes fist at sky and curses PHP some more). The commercial one didn’t really look dramatically more complete and seemed more focused on reading and editing PDFs
So, time to write come code. I needed to test that I could generate a PDF containing some text and lines + images, ideally protect it against alteration and do it all on AppEngine. It turned out that both the OSS libraries worked fine but I ran into problems with gofpdf and it’s limited support for unicode characters which I was going to need to display the symbols on the pattern. The signintech library worked better in this regard but still seemed to choke with certain characters. I spent some time also looking into the options for symbols - finding characters that looked clear and unambiguous was more difficult than I imagined and, when running some of them past my wife for approval, discovered that this was a frequent source of complaints online … a pattern might have a circle symbol for one color and a slightly larger circle for another, very confusing.
proof that I could render a PDF:
Edited to add: Oops, I guess the code I added to my custom blog-engine to stop deep-linking to files works - the link to the PDF file from another site redirects you to the webpage associated with them instead … the links to the PDFs near the bottom of that page should let you see the example file.
Not only was deciding a symbol difficult, but finding a font that supported the assortment of symbols from across the unicode spectrum was a challenge - to display consistently on different devices means having the font available. Otherwise what is a black and white smiley face on a desktop might become a colorful smiley emoji on a phone. I finally got down to Everson Mono and Google’s Noto as options and Noto looked like the winner. The symbols I used in the PDF would also need to be displayed in the viewer so having web fonts available was important but I also discovered I’d be able to generate my own smaller subfont (just the glyphs I used) or could also use SVG if I needed.
PDFs were viable and if I ran into problems, I could always resort to using SVG or images instead.
Authentication
One of the requirements is to provide sign-in through people’s existing social network accounts - Google, Facebook and Twitter. Apart from removing friction from the sign-up process, it also means you outsource all your account security to the companies that provide those accounts which have more resources to do it properly than I do. It also saves writing all that user-account management code that every system used to need - sure, you could pull it in as a library but it’s still something to maintain and manage and data that needs to be stored securely.
But, there are still options for how you connect to the 3rd party accounts. Developing a complete OAuth service is definitely doable and, in some cases, is justifiable. I need very little beyond the ability for users to identify themselves to the system so that I can associate them to their data so just need a service I can use to do the sign-in and give me an identifier.
A few companies offering Sign-in as a Service have come and gone over the years which has always made me slightly nervous about relying on 3rd party providers for this but others such as Auth0 have been around for a while and look pretty robust. They also provide lots of great resources, libraries and how-to articles to learn more about OAuth, JWT (Javascript Web Tokens) and using them from various frameworks.
For this app though I ultimately decided to go with Firebase for a few reasons:
- I have recent experience using it
- It’s Google powered and integrates with the cloud platform (its file storage is the same bucket that your appengine project creates)
- There are web-components to use it from Polymer
- The authentication part is free
I’ve already written some code to verify Firebase authentication tokens on the server from Go so know I’ll be able to verify the user identity of any call if I need to (a PDF request for instance).
Structured / Metadata Storage
What system would do much without some structured data? I know I’m going to need to store some extra information about a pattern than just the pixels and will also have Orders and other things to save as well. In fact, I sketched up a rough Entity diagram(ish) to show what I was envisioning:
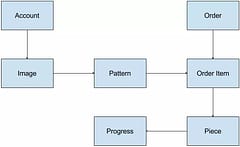
The Account is the owner of a set of Images (this could be where things are white-labelled for other companies or artists to create their own stores).
Each image can have patterns created from it, possibly at different resolutions and color limits, with different filters applied like Sepia or Greyscale and linked to a particular thread manufacturer like DMC or Anchor (oh crap, am I really becoming knowledgable about cross-stitching? What next, embroidery?).
Patterns are available for purchase and would then be an Order Item on an Order. This would control whether someone could download the PDF of a pattern. It would also allow people to create a Piece which they could complete using an online pattern viewer (probably on a phone or tablet). I had an idea to let people check off stitches using the viewer (people currently use PDF viewers for this part) and then save the daily version as frames in an animated gif where completed stitches are transparent to let the pattern pixel show through and uncompleted stitches are white (the typical fabric color). This would provide a cool animated progress display that people could share and get some encouragement from. Gamification stats could also come from this progress information.
The metadata itself isn’t complex, but where should it all be stored? If I use a relational database, even MySQL, it’s going to cost money and it always adds work and maintenance so I discount that as an option straight away. I want a cloud service, not database instances.
Google Cloud has a NoSQL datastore that has a free tier for the first 1Gb of data, is still ridiculously cheap after that ($0.18 per Gb month) and is a fully managed service so zero maintenance and unlimited scalability. The downside would be the need to develop a REST API to provide access to it.
There’s also Firebase realtime database and this is very tempting because I’m already using the authentication and pulling in the libraries for it plus it’s serverless which is “the new cool thing” (meh) which means I could just start using it without having to write any API - that’s what it is already. While it’s convenient though, it is considerably more expensive ($5 per Gb + bandwidth) and there’s little about the app that really demands the real-time aspect of it.
I decided to put together a couple of pages to save & display some data and compare the two. The performance difference wasn’t noticeable for the type of use I was putting things to and one important aspect was that I was going to need to read and write the data from the server (both the PDF generator and payment processing) which made me lean toward the datastore solution.
Firebase was great and it worked well but I felt like I’d be paying for a feature I really didn’t need and couldn’t accurately predict the usage and costs. Given that I have a lot of Go code already from other projects to put together a solid REST API and know how reliable and inexpensive datastore is to use, I decided to go with that.
Payment Processing
I kept this one till last because it’s the easiest to choose: Stripe - I’ve used it before, it has a great API, it avoids having to let credit-card information anywhere close to touching your server (great for security / PCI compliance) and they support payment from more currencies than I even knew existed. I already had an account from using it with other projects which sure, might have also swung it in their favour, but I’ve used other payment processing in the past - Moneris, PayPal and several others, and Stripe is by far my favourite and now my goto option every time.
They provide a slick checkout UI widget that runs on the client, communicates with their servers to store the users payment information before passing back a token that you can send to your server where you need to confirm the transaction. Very easy, very secure and also delivers a great experience for end users to pay with whatever card and currency they want (even Bitcoin). Whatever they use, Stripe handles all the currency conversion for you and deposits the payments into your account on the schedule you set (e.g. rollup all payments each day, week or month).
If I want to let other people use the system for their own stores, they also have some neat features for splitting off parts of a payment as a platform fee. Or, I might have to pay a commission to artists for sales based on their images - Stripe provide the building blocks for these kinds of scenarios all within a single payment transaction.
Final Design
I had to do a few experiments to verify and decide on some of the pieces but finally picked a set of technologies based on a combination of existing personal experience, functionality and price:
- The user-interface will be developed using Web Components enhanced with Polymer and will use Firebase for authentication.
- Structured data will be stored in Google Cloud Datastore and image blobs in Google Cloud Storage.
- The REST API to handle data, payment processing and PDF generation will be developed in Go and running on AppEngine
Total estimated cost for our micro-startup: $0 per month. Perfect!
Next up will be some interesting implementation details that were needed along the way.