SvelteKit Hydration Gotcha
Avoiding accidentally large payloads
Contents
Introduction
SvelteKit makes loading data, server-side rendering it, and hydrating it on the client to then run as a client-side app incredibly easy. It’s so easy, you may not notice you accidentially made your page inefficient. In extreme cases you could be including massive payloads that consume bandwidth and slow things down, but everything will continue to work as normal.
Basic Data Loading
Imagine a discussion forum app, we may have a “subject” page that lists matching topics, with pagination options set via URL searchParams. The data can be loaded on the server using a load function like this:
/src/routes/subject/[id]/+page.server.ts
import { getTopicsForSubject } from "$lib/datastore"
export async function load({ params, url }) {
const { id } = params
const topics = await getTopicsForSubject(id, url)
return {
topics
}
}NOTE: the getTopicsForSubject implementation isn’t important for this discussion, all that matters is that it handles loading the relevant data.
The data returned from the load function is passed to the page where it can be rendered:
/src/routes/subject/[id]/+page.svelte
<script lang="ts">
import TopicNavigation from '$lib/TopicNavigation.svelte'
iport TopicSummary from '$lib/TopicSummary.svelte'
export let data
$: topics = data.topics
</script>
<TopicNavigation {topics} />
<ul class="space-y-4">
{#each topics as topic (topic.id)}
<TopicSummary {topic} />
{/each}
</ul>
<TopicNavigation {topics} />Again, the rendering code doesn’t matter so much so we’ll hand-wave that away by just delegating the work to Svelte Components who’s implementation isn’t shown.
We run our page, and we get our expected content. Imagine it looks like this (taken from TailwindUI components):

Job done, we commit our code and move on to the next task.
The Potential Problem
What problem, it looks fine? Yes, it looks fine, and it works fine, but you decide to check the network tab and discover that the SSR version of the pages is 3Mb+ in size.
Uh?! How can it take 3Mb to render those few things?
It all comes down to the data and how SvelteKit hyration works. When a page is Server-Side Rendered, the page contains the HTML rendered version and also the data used to render it which is used to hydrate the client-side version of the page (so the components running on the client have the matching data, just as they did when they ran on the server). If you view the page source you’ll see in a <script> block near the end the JSON-like data embedded (its actually using a lib called devalue which handles serializing JS Date objects besides other things, which regular JSON can’t).
But it’s not just the data that we use that is serialized. It’s all the data that was returned from our load function.
The potential problem is that the data could contain far more than we’re using.
Imagine the ‘shape’ of the Topic returned from our data layer:
interface Author {
id: number
name: string
avatar: string
}
interface Topic {
id: number
title: string
author: Author
started: Date
updated: Date
replies: {
author: Author
posted: Date
markdown: string
html: string
ip_hash: string
country: string
}[]
}We use some of that data to render the page, but not all of it, so the size of the payload that’s embedded into the SSR’s HTML could be much larger than needed.
In extreme cases it could be megabytes of extra data that isn’t used. This will slow down the transfer of the page to the client, and the time it takes to re-hydrate to allow interaction.
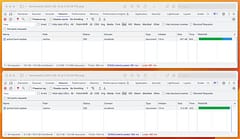
Here’s two requests for the exact same page view, showing the issue. Note the total payload size at the bottom of the page - 3.2MB vs 22kB (because it’s running locally, the download time isn’t impacted as much as it otherwise could be going over the wire):
We could also accidentially be exposing data to the client that we don’t want to. Suppose the replies didn’t contain an ip_hash but instead the actual IP … even though it isn’t displayed on the page, it would be visible to anyone who viewed the page source.
The Solution
The solution is to only return the information we actually use. In this case, we don’t need all the replies, or the content of the replies - we just need a total count and the last 5 authors. If we transform the full Topic to a TopicSummary instead, we can potentially save a lot of data being sent over the wire:
interface Topic {
id: number
title: string
author: Author
started: Date
updated: Date
total_replies: number
latest_replies: {
author: Author
posted: Date
}[]
}By having a clear model of the data that we want to go to the front-end, which may be different to the data in the database, we get the benefits:
- Fewer CPU cycles to serialize the data and http compress it
- Quicker initial page load and navigation between pages
- Less bandwidth consumed (both both the host and the client)
- Faster re-hydration on the client
So, always think about exactly what data your page needs and whether sending the extra is worth it. There may be times when it is - you may, for instance, want to send data at the layout level that would be used within child routes without them having to fetch the additional content. But it’s worth testing to make sure that you’re not over-fetching data and adversely impacting performance as a result.