Simple Service Bus / Message Queue with MongoDB
Contents
Introduction
A service bus or message queue allow producers and subscribers to communicate asynchronously so that a system can handle disconnects, processes being stopped and started or enable peaks of demand to be handled beyond what the subscriber can immediately cope with. The queue acts as a buffer that the producer writes to and the subscriber reads from.
There are lots of implementations such as NServiceBus, MassTransit, Rhino Service Bus and the cloud-provided services such as Amazon’s Simple Queue Service and Window Azure’s AppFabric Service Bus. Some take a little time to get started with and the cloud ones can also rack up charges pretty quickly if you are doing too much polling.
Often, all that is needed is something fairly simple to buffer messages between processes and persist them. I’ve been making good use of MongoDB recently in conjunction with Jonathan Oliver’s EventStore library for a CQRS-based project so it seemed the obvious place to start – why not use MongoDB to store the queue?!
Now, I did have a look round first to see if anyone else had created something already and the closest I got was the post here: Why (and How) I Replaced Amazon SQS with MongoDB. However, from reading the MongoDB website I’d seen that it had Tailable Cursors which, together with the Capped Collections feature, seemed like the ideal tools to build a queue on and possibly more efficient – in fact, MongoDB uses these very features internally for its replication.
Why are these features important?
We don’t want the queue to just grow and grow and grow but would like to put a cap on the size. Once a capped collection in MongoDB is full it wraps round and starts overwriting the oldest records. Capped collections are actually pre-allocated which helps with performance too. All we need is a collection that will be big enough to cope with any downtime from the subscriber so that messages are not lost.
Capped collections also support natural sort order where you can read records in the order they were written to which means we don’t need an index which means both reads and writes will be much faster without MongoDB having as much extra work to do.
Tailable cursors block at the server so we don’t have to keep polling or have to give up some latency. If a cursor is opened and there is no data to return it just sits there waiting but will fire off the next record to you as soon as it comes in (actually, it doesn’t wait indefinitely but somewhere around 4 seconds but the result is the same – we only ‘poll’ every 4 seconds but get immediate notification of a new message).
So, with the newly released Official C# MongoDB Driver in hand I set-out to build my queue …
Before the details though, you can take a look at the finished result from this Jinq screen-cast:
We’ll try and keep things really simple for this example so welcome to the simplest queue interfaces ever conceived! We just have an interface for adding things to the queue and another for reading from it:
public interface IPublish<in T> where T : class
{
void Send(T message);
}
public interface ISubscribe<out T> where T : class
{
T Receive();
}
And of course we need something to actually send – again, we’ll keep things simple for the demo and have a very simple message with a couple of properties:
public class ExampleMessage
{
public int Number { get; private set; }
public string Name { get; private set; }
public ExampleMessage(int number, string name)
{
Number = number;
Name = name;
}
public override string ToString()
{
return string.Format("ExampleMessage Number:{0} Name:{1}", Number, Name);
}
}
The ExampleMessage will be the generic <T> parameter to the queue interfaces but we’re going to want to store a bit more information in MongoDB than the message itself so we’ll also use a MongoMessage class to add the extra properties and act as a container / wrapper for the message itself. Nothing outside of the queue will ever see this though:
public class MongoMessage<T> where T : class
{
public ObjectId Id { get; private set; }
public DateTime Enqueued { get; private set; }
public T Message { get; private set; }
public MongoMessage(T message)
{
Enqueued = DateTime.UtcNow;
Message = message;
}
}
This will give each message that we send an Id and also record the date / time that it was enqueued (which would enable us to work-out the latency of the queue). The Id is an ObjectId and this is the default Document ID type that MongoDB uses. All of the messages that we write to our queue will be assigned an Id and these should be sortable which we can use to pick up our position when reading from the queue should we need to re-start.
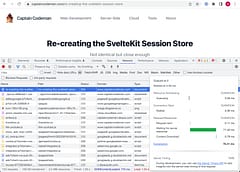
Here is what the messages look like inside of MongoDB (via the excellent MongoVUE GUI tool):

With the interfaces and commands in place we can add a couple of projects to show how each side will be used. First the producer which will just write commands to our queue:
class Program
{
private static readonly ManualResetEvent Reset = new ManualResetEvent(false);
private static long lastWrite;
private static long writeCount;
private static Timer timer;
private static readonly object _sync = new object();
static void Main(string[] args)
{
Console.WriteLine("Publisher");
Console.WriteLine("Press 'R' to Run, 'P' to Pause, 'X' to Exit ...");
timer = new Timer(TickTock, null, 1000, 1000);
var t = new Thread(Run);
t.Start();
var running = true;
while (running)
{
if (!Console.KeyAvailable) continue;
var keypress = Console.ReadKey(true);
switch (keypress.Key)
{
case ConsoleKey.X:
Reset.Reset();
running = false;
break;
case ConsoleKey.P:
Reset.Reset();
Console.WriteLine("Paused ...");
break;
case ConsoleKey.R:
Reset.Set();
Console.WriteLine("Running ...");
break;
}
}
t.Abort();
}
public static void Run()
{
IPublish<ExampleMessage> queue = Configuration.GetQueue<ExampleMessage>();
var i = 0;
while (true)
{
Reset.WaitOne();
i++;
var message = new ExampleMessage(i, "I am number " + i);
queue.Send(message);
Interlocked.Increment(ref writeCount);
if (i == int.MaxValue)
i = 0;
}
}
public static void TickTock(object state)
{
lock (_sync)
{
Console.WriteLine("Sent {0} {1}", writeCount, writeCount - lastWrite);
lastWrite = writeCount;
}
}
}
… and the consumer which will read from the queue:
class Program
{
private static readonly ManualResetEvent Reset = new ManualResetEvent(false);
private static long lastRead;
private static long readCount;
private static Timer timer;
private static readonly object _sync = new object();
static void Main(string[] args)
{
Console.WriteLine("Subscriber");
Console.WriteLine("Press 'R' to Run, 'P' to Pause, 'X' to Exit ...");
timer = new Timer(TickTock, null, 1000, 1000);
var t = new Thread(Run);
t.Start();
var running = true;
while (running)
{
if (!Console.KeyAvailable) continue;
var keypress = Console.ReadKey(true);
switch (keypress.Key)
{
case ConsoleKey.X:
Reset.Reset();
running = false;
break;
case ConsoleKey.P:
Reset.Reset();
Console.WriteLine("Paused ...");
break;
case ConsoleKey.R:
Reset.Set();
Console.WriteLine("Running ...");
break;
}
}
t.Abort();
}
public static void Run()
{
ISubscribe<ExampleMessage> queue = Configuration.GetQueue<ExampleMessage>();
while (true)
{
Reset.WaitOne();
var message = queue.Receive();
Interlocked.Increment(ref readCount);
}
}
public static void TickTock(object state)
{
lock (_sync)
{
Console.WriteLine("Received {0} {1}", readCount, readCount - lastRead);
lastRead = readCount;
}
}
}
Both show the total number of messages sent or received and also the number in the last second.
Finally, the MongoQueue implementation. It could be a little simpler but I wanted to make sure things were as simple as possible for the consumers and should be easy enough to follow.
public class MongoQueue<T> : IPublish<T>, ISubscribe<T> where T : class
{
private readonly MongoDatabase _database;
private readonly MongoCollection<MongoMessage<T>> _queue; // the collection for the messages
private readonly MongoCollection<BsonDocument> _position; // used to record the current position
private readonly QueryComplete _positionQuery;
private ObjectId _lastId = ObjectId.Empty; // the last _id read from the queue
private MongoCursorEnumerator<MongoMessage<T>> _enumerator; // our cursor enumerator
private bool _startedReading = false; // initial query on an empty collection is a special case
public MongoQueue(string connectionString, long queueSize)
{
// our queue name will be the same as the message class
var queueName = typeof(T).Name;
_database = MongoDatabase.Create(connectionString);
if (!_database.CollectionExists(queueName))
{
try
{
Console.WriteLine("Creating queue '{0}' size {1}", queueName, queueSize);
var options = CollectionOptions
// use a capped collection so space is pre-allocated and re-used
.SetCapped(true)
// we don't need the default _id index that MongoDB normally created automatically
.SetAutoIndexId(false)
// limit the size of the collection and pre-allocated the space to this number of bytes
.SetMaxSize(queueSize);
_database.CreateCollection(queueName, options);
}
catch
{
// assume that any exceptions are because the collection already exists ...
}
}
// get the queue collection for our messages
_queue = _database.GetCollection<MongoMessage<T>>(queueName);
// check if we already have a 'last read' position to start from
_position = _database.GetCollection("_queueIndex");
var last = _position.FindOneById(queueName);
if (last != null)
_lastId = last["last"].AsObjectId;
_positionQuery = Query.EQ("_id", queueName);
}
public void Send(T message)
{
// sending a message is easy - we just insert it into the collection
// it will be given a new sequential Id and also be written to the end (of the capped collection)
_queue.Insert(new MongoMessage<T>(message));
}
public T Receive()
{
// for reading, we give the impression to the client that we provide a single message at a time
// which means we maintain a cursor and enumerator in the background and hide it from the caller
if (_enumerator == null)
_enumerator = InitializeCursor();
// there is no end when you need to sit and wait for messages to arrive
while (true)
{
try
{
// do we have a message waiting?
// this may block on the server for a few seconds but will return as soon as something is available
if (_enumerator.MoveNext())
{
// yes - record the current position and return it to the client
_startedReading = true;
_lastId = _enumerator.Current.Id;
_position.Update(_positionQuery, Update.Set("last", _lastId), UpdateFlags.Upsert, SafeMode.False);
return _enumerator.Current.Message;
}
if (!_startedReading)
{
// for an empty collection, we'll need to re-query to be notified of new records
Thread.Sleep(500);
_enumerator.Dispose();
_enumerator = InitializeCursor();
}
else
{
// if the cursor is dead then we need to re-query, otherwise we just go back to iterating over it
if (_enumerator.IsDead)
{
_enumerator.Dispose();
_enumerator = InitializeCursor();
}
}
}
catch (IOException)
{
_enumerator.Dispose();
_enumerator = InitializeCursor();
}
catch (SocketException)
{
_enumerator.Dispose();
_enumerator = InitializeCursor();
}
}
}
private MongoCursorEnumerator<MongoMessage<T>> InitializeCursor()
{
var cursor = _queue
.Find(Query.GT("_id", _lastId))
.SetFlags(
QueryFlags.AwaitData |
QueryFlags.NoCursorTimeout |
QueryFlags.TailableCursor
)
.SetSortOrder(SortBy.Ascending("$natural"));
return (MongoCursorEnumerator<MongoMessage<T>>)cursor.GetEnumerator();
}
}
After opening a cursor we get an enumerator and try to read records. The call to MoveNext() will block for a few seconds if we’re already at the end of the cursor and may then timeout without returning anything. In this case we need to dispose of the enumerator and get another from the cursor but we don’t need to re-run the query – it’s still connected and available and we just need to ‘get more’ on it.
The reason for the _startedReading flag is that the initial query against an empty collection will result in an invalid cursor and we need to re-query in this case. However, we don’t want to re-query after that as it’s more efficient to let the cursor wait for additional results (unless the cursor is dead when we do need to re-query).
Occasionally, the connection will be broken which will cause an exception so we need to catch that and setup the cursor and enumerator again.
Assuming we got a record back then we return it to the client (yield return) and go back to get the next item. We also store the position of the last item read in the queue so that when we re-start we can skip any existing entries.
Here is an explanation of the query flags.
Query Flags:
AwaitData
If we get to the end of the cursor and there is no data we’d like the server to wait for a while until some more arrives. The default appears to be around 2-4 seconds.
TailableCursor
Indicates that we want a tailable cursor where it will wait for new data to arrive.
NoCursorTimeout
We don’t want our cursor to timeout.
So there it is – a simple but easy to use message queue or service bus that hopefully makes splitting an app into multiple processes with re-startability and fast asynchronous communication a little less challenging. I’ve found the performance of MongoDB to be outstanding and ease of setting this up beats the ‘proper’ message queue solutions. When it comes to the cloud, the small amount of blocking that the cursor does at the server saves us having to do a lot of polling while still giving us the fast low-latency response we want.
Please let me know what you think of the article and if you run into any issues or have any ideas for improvement for this approach.
UPDATED: Source code now on GitHub (https://github.com/CaptainCodeman/mongo-queue)