Web Development and Cloud Computing
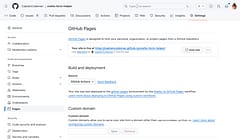
There are already a few guides on how to deploy your SvelteKit application to GitHub Pages but many are more complex than they need to be. This guide shows an easy way to do it with less configuration.
SvelteKit makes web development easy. So easy, you may not notice that you accidentally added some inefficiency. Learn what to look for and how to easily avoid it.
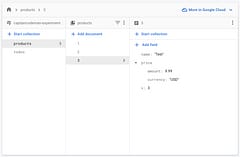
NoSQL doesn't mean no-schema, it means each entity has it's own schema so you may end up with more than one. Learn how Schema Versioning helps bring order to chaos and how to use it with Google Firestore
Using Intl to format dates and numbers on a purely client-side app is easy, but adding SSR can result in a flash of wrongly-styled content. Learn how to perfectly format SSR content to match the users locale
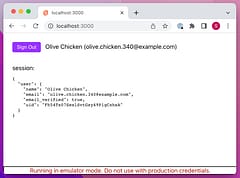
Support for async await is baked into Svelte templates but when you're using SvelteKit, you may need to wait for auth to settle in a load function which can lead to subtle gotchas.
When Static Site Generation isn't an option adding output caching can provide similar benefits. This shows how to cache SvelteKit pages in Redis
With the removal of the session store from SvelteKit, it's now a build-your-own adventure. Learn some ways to restore it's functionality.
Avoid wasteful state re-calculations and re-renders when using SvelteKit page data from $app/stores
How to use Svelte Stores for lazy-loading of Firebase Firestore SDK and data with an easy approach to control query parameters.
How to create Headless or Renderless Components with Svelte to allow you to combine your own HTML markup and CSS styling with read-made behaviors for interaction and Aria Accessibility.
The new modular Firebase SDK is better than it was but can still bloat your JS bundle to adversely affect your Lighthouse score and Core Web Vitals. Learn how to lazy-load for faster startup.
Why does Redux require so much boilerplate? Why is it such a chore to use? Can't we have an easy to use state store without the complexity? You can - with Rdx